導入実績がある業務効率化のAzure構築を紹介します。
申請書・領収書(PDFファイルなど)をOCRで読み取って、読み取ったテキストデータをチェックしたりデータベースに登録したりする、業務効率化システムの作り方です。

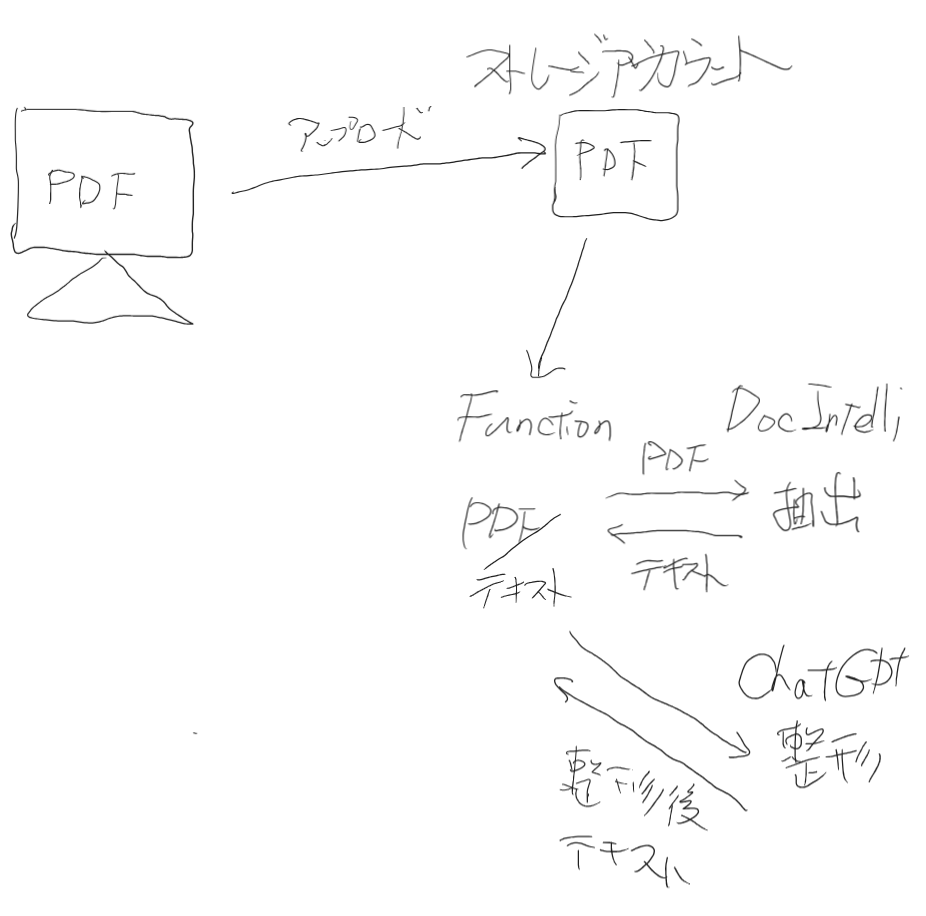
最初に、具体的なAzure構築内容・流れを見せちゃいます。
- AzureStorageAccountにPDFがアップロードされたらAzureFunctionsのアプリが実行
- AzureFunctionsのアプリ処理の中でAzureDocument IntelligenceのOCR-APIを呼び出してPDFからテキストを抽出する
- ChatGPT-APIを呼び出す際のスクリプトは期待する値だけ取得できるようにフォーマットを指定したりして作る
- テキストデータとスクリプトを指定してChatGPT-APIを呼び出すことで、OCRで抽出したテキストから期待する値を扱えるようにする
- 期待するフォーマットで取得した値をアプリ処理でチェックやDB登録などのやりたい処理を作る
(5. のやりたい処理は、ご自身で考えてFunctionsアプリにコーディングする必要があります)
PDFからテキストデータを抽出 (OCR)
まずAzureDocumentIntelligenceというサービスのOCR機能を使って、PDFからテキストデータを抽出します。具体的に言うと、AzureDocumentIntelligenceがAPIを提供しているので、PythonプログラムなどからAPIを呼び出すことでOCRで抽出されたテキストデータが取得できます。
この画像を読み込ませると・・・

一部省略しますが、以下が取得したテキストです。手書きのところも、読んでくれていますね。
Paragraph:
様式第3号
==========
Paragraph:
2025年2月9日
==========
Paragraph:
氏 名
==========
Paragraph:
山本太郎
==========
Paragraph:
(担当者氏名) 電話
==========
Paragraph:
080-1234-5678
懸念点
取得したテキストをプログラム処理で読み取って使用することになると思いますが、PDFのフォーマットが複数あるとフォーマットごとにプログラム処理を用意する必要が出てくるかもしれません。日付や名前が何番目に表示されているかバラバラだと、一つのプログラム処理では対応できないですよね。ただ、概ね並んでいる項目並んでいる順番が似ているのであれば問題ありません。なぜ問題ないかというと、プロンプト次第ではChatGPTは柔軟に情報を読み取ってくれるので、頑張ってプロンプトを作製してChatGPTに良しなに読み取って値を返してもらうことで、期待するフォーマットの値を取得・使用することができます。 ただ、フォーマットがバラバラだったり、手書きの字が汚くてOCR機能で読み取れなかったりする場合は、フォーマットの統一や手書きを止めるなどの根本的な変更が必要になる場合も考えられます。
指定フォーマットで値を取得 (ChatGPT)
次にChatGPTを使います。なぜChatGPTを使うかというと、OCR機能が読み取ったテキストデータそのままだと、必ずしも人間が目で見える値で取得できるとは限らないからです。なのでそのままチェック処理に使ったり、DB登録はできない可能性が高いということになります。具体例を言うと、手書きで書いた人によっては、令和6年と書いたり2025年と書いたり、数字も漢数字で書いてあるかもしれません。申請書や領収書を書く人に書き方ルールを伝えて、必ず同じ書き方がされるようにコントロールできれば良いのかもしれませんが、それはなかなか難しいと思いますので、ChatGPTの力を借りてばらけた書き方のデータを同じフォーマット同じ書き方のデータに書き換え・整形してもらうことが必要になります。
懸念点 (スクリプトの書き方)
ChatGPTを使うときにスクリプトを書く必要があることはご存知だと思います。この場合も同様にやって欲しいこと、やって欲しくないことなどを厳密に書く必要があります。どんなインプットデータを渡してもご自身が期待している値を必ず返してくれるスクリプトを作り上げる必要があります。少しサンプルスクリプトを書いてみましたので、以下に載せておきます。
チェック処理やデータベース登録
ここまでの流れで、PDFから読み取ったテキストデータが自分で扱いたいフォーマットになりました。その後はチェック処理に使ったり、そのままデータベースに登録したり、好きな処理を実装すれば良いという流れになります。
以上です。